Consolidating our enterprise data in the Azure Data Lake to enrich our data-driven solutions
Knowledge is power, and in business knowledge comes from data-driven insights. We are often accustomed to having an onlook into our data in singular applications, separated from each other, even though their data is contextually connected and related: A sales system, a billing system, various production pipelines and a logistics system, just to name a few.
We may have powerful reports on our sales pipelines, and another set on production or logistics, and these reports do provide us with information on how these processes work in vacuum. But the truth is that nothing happens in a vacuum, instead, everything we do is connected.
To give you an example, our sales are driven, among other things, by customer satisfaction. Customer satisfaction can be boosted by providing high quality products and services in time without delays. Problems in our logistics chains can cause delays in both production and delivery, which makes our customers unhappy. Same goes doubly for any issues during production – maybe the devices used in quality assurance were poorly configured and we shipped low quality products as a result?
Customer satisfaction goes further down and landing new sales deals becomes more difficult. But if we looked at the data from our sales processes on its own, we would only end up seeing the result of sales going down – and not the actual, underlying cause of poor customer satisfaction, which was in turn caused by poor performance in production.
In this blog post I will show you how we can use Microsoft’s Azure services to consolidate all of the aforementioned enterprise data, and more, from different sources together to create even more powerful data-driven solutions. For the previous post on my series on Microsoft’s data platform, please see Building a real-time, cloud-based monitoring solution using Power BI and Microsoft’s data offerings.
Case: Combined dashboards on the full sales-to-delivery chain with Azure Data Lake
Consolidating data between systems can often seem like an insurmountable task. There are the technical challenges of managing multiple data sources and formats and combining them together in a meaningful way, and then there are the semantic challenges of finding relationships between different systems: How do we relate a customer in our sales pipeline to the same customer in our logistics system? Or what are the product codes for the items we sold in our production systems? Although this may feel like a lot to do before we can get any meaningful end results implemented, I’ve got some good news for you: With Azure it really isn’t that bad.
At the center of it all lies Azure Data Lake – a service for storing virtually all the data your enterprise ever needs or generates. Data Lake is schema agnostic, meaning that it does not care what format your data is in. It’s preferable that the data is stored in a format which is supported by all of the services involved in your data pipelines.
But other than that storing business data in Data Lake is as simple as extracting it from the source system and saving the extract in Data Lake as-is. And since we are using Data Lake simply as a centralized storage for all of the data coming from our various separated systems, we can implement these data extraction processes independent from each other.
When it comes to implementing a Data Lake solution there is no need for a single massive project where we identify all of the relevant business data at once, perform transformations on it and then copy that one, huge blob to Data Lake. Instead, we will be agile, implementing the data store piece by piece and effortlessly adding new data sources in tiny development projects as they are identified.
In practice the data stored in Azure Data Lake can come from virtually anywhere: Production management databases or documents stored in network file shares in your on-premises networks, Excel files located in Microsoft Teams, data in SharePoint lists, or any non-Microsoft cloud-based systems, provided they have support for extracting data. Just to name a few.
We choose the tools used for integrating these systems into Data Lake on a case-by-case basis as dictated by technical requirements and cost-efficiency. Azure Data Factory is my personal favorite since it can be run in the cloud and optimized for both performance and costs, and with the option of using Databricks it becomes a very powerful product. Other common tools include SQL Server Integration Services (or SSIS) in on-premises, Azure Stream Analytics for real time data or Logic Apps to make use of its Microsoft 365 connectors.
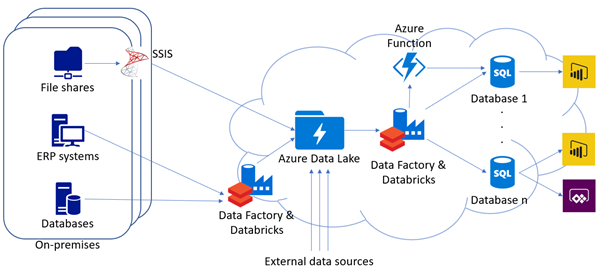
Once our data has been stored in Data Lake, we can get into implementing the actual business solutions. Although it is possible to use Power BI to connect directly into Data Lake, the most common scenario is to implement a database for our solution, ingesting transformed data from Data Lake to this database, and then building the business solutions on top of that.
There are multiple reasons for this: First, we are using Data Lake simply as a storage for our existing data “as-is.” This means that before we can use the data from our various systems – be it sensor data from production management, logistics information or sales data – we likely need to perform transformations on the data to make it all usable together. These transformations are done on this new reporting database.
Second, separating the reporting data source from the initial data storage means we can do changes in the reporting without affecting the data storage layer. Similarly, we can also add new reporting databases for other, separate solutions without affecting our existing databases.
This results in a modular structure where we can have one single Azure Data Lake instance serving multiple separate reporting databases, all of which can be doing their own thing. It is not uncommon to have just one Data Lake in an enterprise and having each business area develop their own reporting databases with their own unique business requirements based on that shared Data Lake.
Since the Data Lake and our reporting databases all are located on the Azure cloud, that is where our transformation logic will reside as well. Copying data from Data Lake to Azure SQL databases is commonly done using Azure Data Factory, which gives us access to a wide array of tools, from Data Flows to Azure SSIS and Databricks, to choose from.
For special cases, such as handling more exotic data formats, we can implement Azure Function Apps to make use of programming code. For the reporting databases we can make use of Azure SQL’s wide array of performance options to find the most suitable solution for our needs: Serverless databases provide excellent price/performance -ratio for reports that are updated once or twice a day, while for more often updated databases provisioned instances can be automatically scaled to meet changing demands.
Now, with our enterprise data combined together in the reporting database we can create the solution layer. For example, we can create a Power BI report with which our production managers can identify delays in our suppliers’ logistics and then use a Power Apps tool to inform our customer service agents that all of the orders affected by this supplier delay might be delayed as well.
They, in turn, can then contact the customers in question and let them know of the potential delay in delivery and possible solutions before it has even occurred, resulting in better customer satisfaction. All of this is possible by being able to match the supplier logistics information with associated production pipelines, production with orders and orders with customers within our reporting database.
The possibilities provided by bringing all of our data together are endless. Do you feel like there might be ways in which your existing business data could be harnessed more effectively? Do get in touch and let’s see what we could do help you!
Writer: Joonas Äijälä